
Sensor de presión 3408560 para Cummins QSK Piezas de motor diesel


Detalles
Tipo de marketing:Producto caliente 2019
Lugar de origen:Zhejiang, China
Marca de marca:Toro volador
Garantía:1 año
Parte no:3408560
Tipo:sensor de presión
Calidad:Alta calidad
Servicio postventa proporcionado:Soporte en línea
Embalaje:Embalaje neutral
El tiempo de entrega:5-15 días
Introducción al producto
Según diferentes métodos de procesamiento de datos, existen tres arquitecturas del sistema de fusión de información: distribuido, centralizado e híbrido.
1) Distribuido: Primero, los datos originales obtenidos por sensores independientes se procesan localmente, y luego los resultados se envían al Centro de fusión de información para la optimización inteligente y la combinación para obtener los resultados finales. Distributed tiene una baja demanda de ancho de banda de comunicación, velocidad de cálculo rápida, buena confiabilidad y continuidad, pero la precisión del seguimiento es mucho menor que la de la centralizada. La estructura de fusión distribuida se puede dividir en una estructura de fusión distribuida con retroalimentación y estructura de fusión distribuida sin retroalimentación.
2) Centralización: la centralización envía los datos sin procesar obtenidos por cada sensor directamente al procesador central para el procesamiento de fusión, lo que puede realizar la fusión en tiempo real. Su precisión del procesamiento de datos es alta y su algoritmo es flexible, pero sus desventajas son altos requisitos para el procesador, la baja confiabilidad y el gran volumen de datos, por lo que es difícil realizarlo;
3) Híbrido: en el marco de fusión de información múltiple híbrido de información múltiple, algunos sensores adoptan el modo de fusión centralizado y el resto adopta el modo de fusión distribuida. El marco de fusión híbrida tiene una fuerte adaptabilidad, tiene en cuenta las ventajas de la fusión y distribución centralizadas, y tiene una fuerte estabilidad. La estructura del modo de fusión híbrida es más complicada que la de los dos primeros modos de fusión, lo que aumenta el costo de comunicación y cálculo.
Filtro Kalman (KF)
El proceso de procesamiento de información por el filtro Kalman es generalmente predicción y corrección. No es solo un algoritmo simple y concreto, sino también un esquema de procesamiento del sistema muy útil en el papel de la tecnología de fusión de información multisensor. De hecho, es similar a los métodos de muchos sistemas para procesar datos de información. Proporciona una estimación estadística efectiva óptima para los datos fusionados mediante un cálculo recursivo iterativo matemático, pero requiere poco espacio de almacenamiento y cálculo, por lo que es adecuado para el entorno con espacio y velocidad de procesamiento de datos limitados. KF se puede dividir en dos tipos: filtro Kalman distribuido (DKF) y filtro Kalman extendido (EKF). DKF puede hacer que la fusión de datos sea completamente descentralizada, mientras que EKF puede superar efectivamente la influencia de los errores de procesamiento de datos e inestabilidad en el proceso de fusión de información.
Imagen del producto

Detalles de la empresa







Ventaja de la compañía
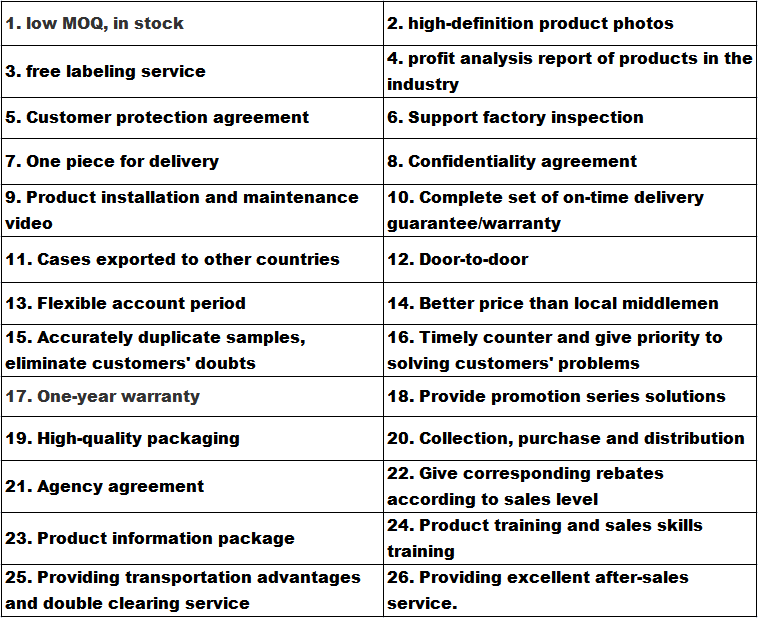
Transporte

Preguntas frecuentes

Productos relacionados








